Information asymmetry, complexity, and structured products
Sorry for the long inactivity, but I am totally caught up in end-of-year wrapping up. I have to admit that I find it quite dissatisfying when you realize the year is almost over and there are still so many things on your list that should have been done… So the last months of the year somehow always end up in total chaos…. anyways…
I came across a very interesting, recent paper (via Mike’s blog post – read also his excellent post) by Arora, Barak, Brunnermeier, and Ge with the title “Computational Complexity and Information Asymmetry in Financial Products” – the authors also provide an informal discussion of the relevance for derivative pricing in practice. As I worked with structured products myself for some time, this paper raised my interest and if you are interested in the trade-off between, say, full rationality and bounded-rationality when it comes to pricing, you should definitely give it a look as well.
The paper deals with the effect of information asymmetry between the structuring entity (which is often also the seller) and the buyer of a structure. The considered derivatives in the paper are CDO like structures and, running the risk of over-simplification, the main points are as follows:
- Having a set of
assets that should be structured into
derivatives, here CDOs, a malicious structurer can hide a significant amount of junk assets when assigning the assets to the derivatives. More precisely, the structurer can ensure that the junk assets are overrepresented in a certain subset of the derivatives to be structured which significantly deteriorates their value.
- A buyer with full-rationality (which can here perform exponential time computations) can actually detect this tampering by testing all possible assignment subsets and verifying that there is actually an/no over-representation.
- On the other hand, a buyer with limited computational resources, say which is only capable of performing polynomial time computations (the standard assumption when considering efficient algorithms that behave well in the size of the input) cannot detect that the assignments of the assets to the derivatives has been tampered.
- Under some additional assumptions, the tampering is even ex post undetectable.
- The authors propose different payoff function that are more resistant to tampering in the sense that heavy, detectable tampering is needed to skew the payoff profile significantly.
Now the authors devise a model similar to Akerlof’s lemons. Stated in a simplified way, the buyer, knowing that he cannot detect the tampering, will assume that a tampering has been performed and is only willing to pay the adjusted price factoring in the potential tampering of the structure – adverse selection. The honest structurer is not willing to sell his derivatives for the reduced price and leaves the market. This effect, based on the information asymmetry between buyer and seller (which was exemplified in Akerlof’s paper using the market of used cars) in the classical setting would lead to a complete collapse of the market as it would repeat ad infinitum until nobody would be left willing to trade. Countermeasures stopping this vicious circle are warranties in the case of the cars. The variant considered here for the structured products will likely converge to the point where the maximum amount of tampering has been performed and buyers and sellers expectations or levels of information are aligned.
What particularly fascinated me is the type of problem encoded to establish intractability. Contrary to the classical NP-hard problems known in optimization that mostly ask for some kind of an optimal combinatorial solution, the authors use the densest subgraph problem/assumption which asserts that deciding between two random distributions (here the fair one and the tampered one) cannot be done in polynomial time (provided that the tampering is not too obvious). In particular:
Densest subgraph problem. Let 
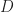

which is obtained by choosing for every vertex in
which is obtained by first choosing
and
with
and
, and then choosing
, and
random neighbors for every vertex in
random additional neighbors in
for every vertex in
Then the densest subgraph assumption states that whenever, 

Densest subgraph assumption. Let 


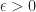

Note that the vertices
In particular, if a group put out 1000 groupings of financial instruments, and I needed to solve the densest subgraph problem on the resulting instance, I would work very hard at getting an integer program, constraint program, dynamic program, or other program to actually solve the instance (particularly if someone is willing to pay me millions to do so). If the group then responded with 10,000 groupings, I would then simply declare that they are tampering and invoke whatever level of adverse selection correction you like (including just refusing to have anything to do with them). Intractable does not mean unsolvable, and not every size instance needs more computing than “the fastest computers on earth put together”.
Another point might be that there are potentially billions of ways of tampering structured products. Especially when the payoff profiles are highly non-linear (e.g., FX-ratchet swaps with compounding coupons) deliberate over-/underestimation of parameters might completely change the valuation of the structures. The proposed framework highlights that there might be ways of tampering that we cannot detect in the worst case, even ex-post (under additional assumptions). But before we can actually detect tampering we have to be aware of this kind of tampering and we have a real problem if tampering is undetectable ex post – how to prove it? This is in some sense related to the stated open question 3: Is there an axiomatic way of showing that there are no tamper-proof derivatives – slightly weakened: with respect to ex-post undetectability.
I could also very well imagine that when giving a closer look to traded structures (especially the nasty OTC ones), that there will be more pricing problems that are essentially intractable. It is almost like one of the main hurdles so far to establish intractability was the more stochastical character of prizing problems while hardness is often stated in terms of some kind of combinatorial problem. An approach like the one proposed in the article might overcome this issue by establishing hardness via distinguishing two distributions.

[…] Source […]
Information asymmetry, complexity, and structured products « Economics Info
October 28, 2009 at 5:02 am
[…] “Computational Complexity and Information Asymmetry in Financial Products” (see also here). The authors argue that already small estimation errors in correlation and probability of default […]
The impact of estimation error on CDO pricing « Sebastian Pokutta’s Blog
December 6, 2009 at 4:32 pm